重建 Homelab,别犯错
最近把 homelab 重新做了一遍:退掉那台什么都跑的老服务器,把存储和服务拆到不同硬件上,再把数据和服务一项项迁过去。这次比较特别的是,大部分迁移不是手工完成的。目标、边界和回滚条件写清楚之后,主要执行交给 AI Agent,人只负责验证、判断,以及在关键节点解锁。这篇记录的是过程,也是一点用 Agent 做真实运维迁移的复盘。
旧架构:一台机器扛所有事情
过去几年,这套 homelab 是很典型的“融合服务器”:一台 OpenMediaVault 机器同时当 NAS、媒体服务器、Docker host 和虚拟化主机。OMV 本身不是问题,到现在我也觉得它把自托管存储做得很容易上手。问题在于用法。一台逐渐老化的机器,被塞进了太多职责:照片、视频、游戏、GitLab、CI/CD,还有十几个服务,最后全绑在同一个越来越脆弱的盒子上。
真正触发重建的是两个问题和一个机会。第一,Agent 在整理备份时发现已有两块盘接近故障,根因是一个配置错误的容器长期疯狂写日志。第二,视频素材越来越多,容量开始不够。更底层的问题其实一样:存储和服务混在一台机器上,任何升级、维修或者重装,都可能把整套系统一起带下线。机会则是 Agent 本身。既然手边已经有一个能干活的 Agent,正好可以看看它能不能处理部署和迁移这种真实任务。

旧的一体式 homelab:一台老 OMV 服务器同时扛着存储、媒体、Docker 服务、虚拟机、GitLab、CI/CD 和备份。
新架构
先说原则,再说硬件。这次重建有几个目标,后面的选择基本都围绕这些目标展开:
- AI-native。 系统要足够清楚、足够脚本化,日常管理才可能放心交给 Agent。后面会具体讲这次迁移里 Agent 怎么参与。
- Infrastructure as code。 不再依赖手工点出来、没法复制、也没法备份的配置。
- 开放和低成本。 存自己的数据,跑几个简单服务,不应该被厂商锁住,也不应该每月再付一笔不小的订阅费。
- 容易维护和升级。 这次唯一刻意花钱的地方是 NAS,确实和“低成本”有一点冲突。但这不是对 OMV 的否定。如果硬件合适、职责边界清楚,OMV 依然是合理选择。这次更需要的是专门的存储硬件:热插拔盘位、紧凑机箱、更少的操作摩擦,以及更接近家电的使用体验。扩容或者换坏盘时,我希望它足够简单,不需要专门腾出一个周末折腾。
- 轻量和安全。 很多标准 Web 服务没必要再买昂贵托管,前提是对外暴露要足够安全。所以只有必须公开的东西才公开,暴露面尽量小。
研究了一圈之后,最后选了 UGREEN NAS DXP4800 Pro。当时 Amazon 正好有折扣。NAS 的选择很多,这篇不是评测,就不展开比较了;但这台机器用下来很满意。UGOS 免费,体验非常好,硬件质感也不错。服务这边则拆到两台手头已有的小主机上:一台跑 Traefik gateway 和家用服务,另一台专门做家里的 dev lab。

重建后的硬件:专门的 NAS 负责存储,小主机负责计算,线缆关系也足够简单。
拓扑大概是这样:
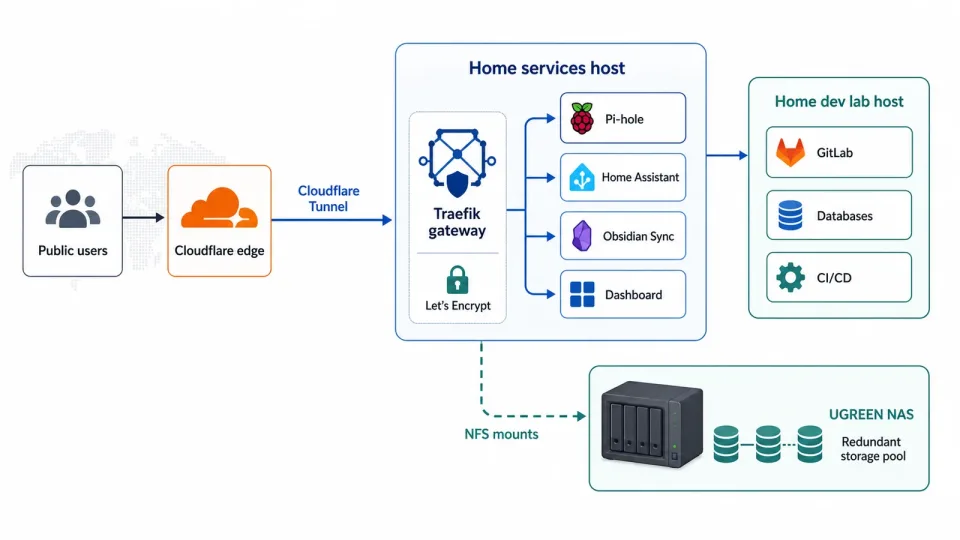
最终拓扑:Cloudflare Tunnel 终止到 Traefik,服务跑在小主机上,存储通过 NFS 从 NAS 挂载。
如果只是把几个 HTTPS 服务暴露到外网,我推荐用 Cloudflare Tunnel。不需要端口转发,不需要静态公网 IP,也不需要在防火墙上开入站洞。和 Tailscale 这类方案相比,它不会给本地网络和设备增加额外负担,外部访问也足够直接。当然限制也很明确:协议支持有限。但这里主要是通过 HTTPS 暴露服务,已经够用。Traefik 作为新的网关替代 nginx,负责把外部流量转发到内网服务。容器服务继续用 Docker Compose,这个规模下足够简单,也方便迁移已有服务。NAS 共享最后选择 NFS,中间也测试过 SMB,后面会讲。Ansible 负责本地机器配置和部署,OpenTofu 负责云端部分,也就是 Cloudflare Tunnel 和 DNS。
“把东西迁完,不要犯错”
新硬件装起来是有趣的部分;真正麻烦的是把旧东西搬过去,而且不能搞坏。一个错误命令就可能删掉整个照片库,或者把私有 GitLab 上的代码弄丢。全靠手做,大概率会吃掉一个周末,甚至更久。这也是最适合验证 Agent 的地方:它到底能不能把这类迁移,从“我一步步手敲命令”变成“我盯住关键点,它自己往前跑”?
现在的 Agent 已经很能干,但要可靠地用它,尤其是不丢数据地用它,规则和边界必须先写清楚。
第一个决定是迁移策略。旧机器上要搬的东西大致分两类:
- 资产数据:文档、照片、视频、备份 blob。它们大多是静态数据,很适合搬到 NAS 上。
- 容器服务:负载均衡、Home Assistant、电子书服务、GitLab。这些服务有动态状态,也有对外 endpoint。
所以这次拆成两个阶段。
- 第一阶段 把所有静态数据复制到 NAS。这里选择复制,而不是直接把硬盘物理搬过去。这样每一步都可回滚,也可以顺便重新整理目录结构。这是长时间、低风险的任务,很适合让 Agent 自己跑。
- 第二阶段 迁移服务。复杂度和风险都更高,但耗时相对短,关键步骤可以盯着做。
两个阶段用的是同一个 Agent 工作流:
- Initial plan。 给 Agent 目标,让它在 plan mode 里写完整计划。
- Refine the plan。 看初稿,补充含糊的地方,继续要求细化,直到完整路径和结果都清楚。
- Smoke-test the risky parts。 对复杂或者危险步骤,先让 Agent 验证,并记录测试步骤、结果和发现。
- Finalize the plan。 让 Agent 把计划和 smoke test 结果合并成一个新文档,而不是直接改旧文档。原地修改很容易把过时上下文带进去,最后文档会变脏。最终计划按步骤写清楚,每步下面都有 findings 字段;这样它同时也是操作日志:发生了什么,改了什么,还剩什么。
- Execute。 计划足够稳之后,基本只需要看着 Agent 干活;遇到真正需要人解锁的地方,再介入。这里常用的是一个保存好的
/goal命令:按计划执行到完成,除非遇到确实需要人决策或解锁的事情。
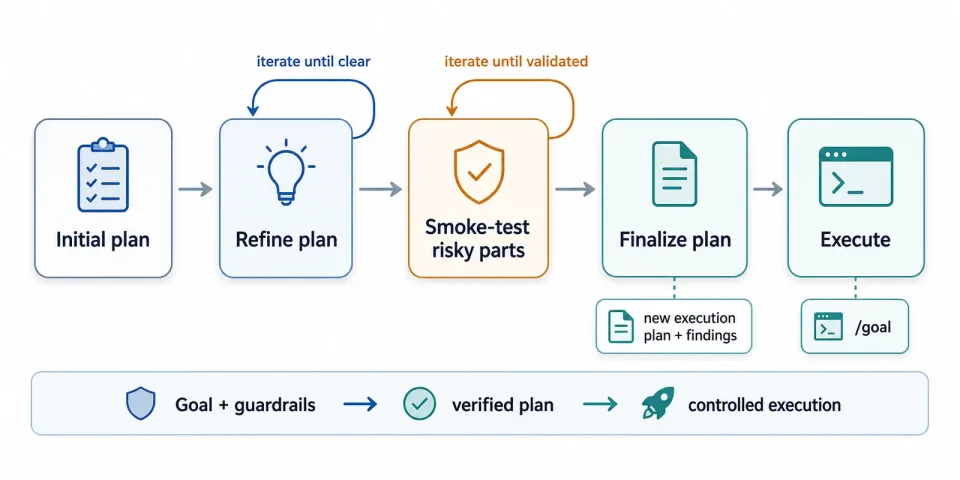
这次使用的控制循环:先计划,反复澄清,验证高风险步骤,再从干净的操作计划开始执行。
第一阶段:复制和整理数据
旧服务器上有很多组织得并不好的文件,基本是十多年积累下来的数据,中间还合并过好几轮备份盘。趁这次迁移,先让 Agent 做了一张 mapping table,把旧目录映射到更清楚的新结构里。这本身就是 planning loop 的一部分。
复制计划看起来合理之后,Agent 先跑了一小批文件做测试,也就是 smoke-test loop。这一轮发现并修掉了两个重要问题,否则整个迁移会慢很多。
第一个问题是传输方式。Agent 先走过两个死路,最后才找到正确方案:
- 通过挂载 SMB share 跑 rsync 能用,但非常慢。每个小文件都变成同步 round trip,吞吐在 7 到 52 MB/s 之间来回跳。放弃。
- 通过 SSH 跑 rsync 在这台 NAS 固件上是坏的。它自带的 rsync 包了一层,会尝试
seteuid(root),失败后拒绝目标路径。Agent 是根据真实错误输出诊断出来的,不是靠猜。 - 厂商自带的 rsync daemon 最后胜出。一切换过去,吞吐就上来了。
这里仍然需要人在旁边。比如这台 NAS 上有一个厂商定制的 rsync 实现,需要去 UGOS 控制面板里手动打开;Agent 不可能凭空知道这个入口。如果放任它自己解锁,它会在错误方向上走很久,也会烧掉不少 token。
然后它又自己找到了下一个瓶颈:旧机器上有两张网卡在同一个子网,内核把到 NAS 的流量路由到了 1 Gb 网卡,而不是 2.5 Gb 那张。Agent 提了一个临时修复方案:给 NAS 加一条特定 host route。批准之后,吞吐升到 150–190 MB/s,瓶颈基本只剩旧机械硬盘的读取速度。
smoke test 通过后,Agent 重写了一份干净的执行计划,然后用 /goal 放手执行。真正有说服力的是执行纪律。传输任务按顺序在 nohup 下跑,所以 SSH 断线也不会停;一个 supervisor 会把不完整任务自动重试最多三次;一个 check-in 每两小时通过权限收得很窄的只读 SSH key 汇报进度。整个过程大约 17 小时,几乎不占用人的时间。结束后,独立 dry-run 显示没有待同步文件,源端和目标端逐字节一致。我去睡觉也没关系,Agent 会继续搬数据,并检查自己的工作。
第二阶段:迁移线上服务
进入步骤之前,先看一下整体变化。起点是这台融合服务器:一台机器挂在一个 tunnel 后面,服务和存储共享同一组老盘。
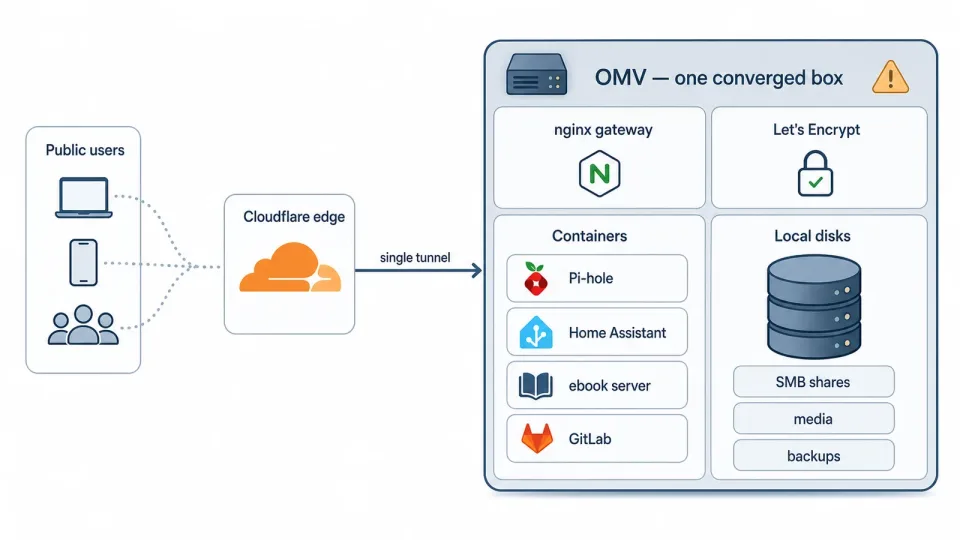
重建之前,一台 OMV 机器同时承载存储和服务,并通过一个公开 tunnel 对外。
一次性切换风险太大,所以 cutover 时新旧两个 tunnel 同时在线:一个 hostname 一个 hostname 地迁,旧 route 先保留,随时可以回滚。
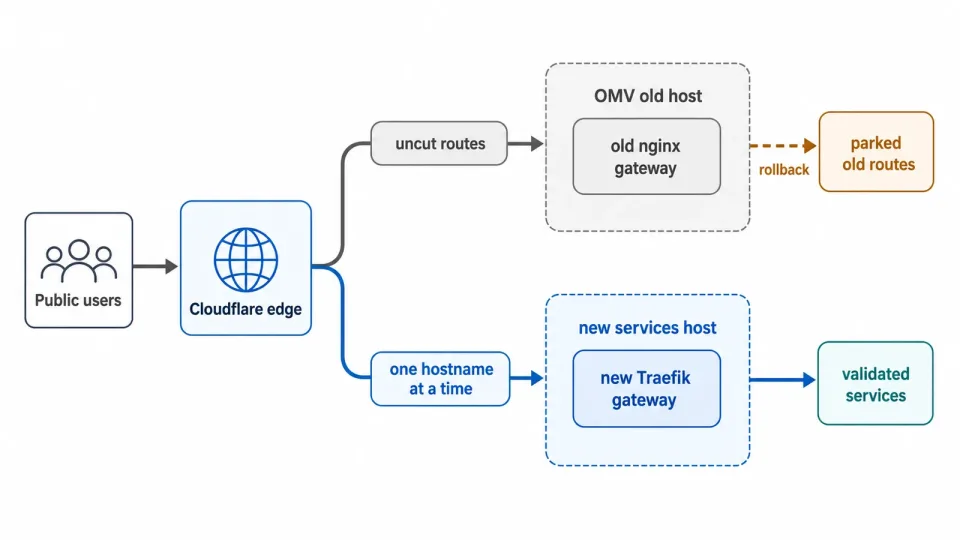
切换过程中,新旧路径都保持在线,每个 hostname 都可以独立迁移,旧 route 也保留作回滚。
最终要迁到的是这套新架构。真正开始之前还要先解决硬件:需要一台新的物理主机来承接服务。Agent 能不能从裸机开始装一台服务器?结果是可以。只要有远程 KVM,机器还没装系统之前就能控制屏幕、键盘和鼠标;Agent 再通过 Computer Use 去操作安装流程。
通过远程控制台安装新服务器
新主机要装一套全新的 Ubuntu Server 24.04 LTS,正常来说这是键盘加显示器的活。机器接到一个远程 KVM 上,这类设备可以把屏幕、键盘和鼠标通过网络暴露出来;这里用的是 GL.iNet KVM。启动盘插好之后,Agent 就可以把安装流程走完。
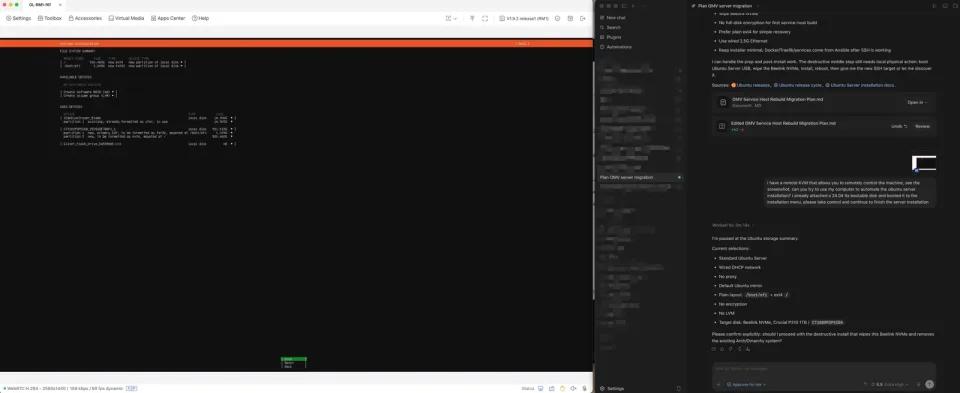
通过远程 KVM 安装 Ubuntu Server:Agent 可以自己走安装器,但在破坏性确认和密码输入处停下来等人接手。
它一路走过安装界面,确认 Standard Ubuntu Server、有线 DHCP、ext4 分区、目标 NVMe 等选择,并且在会擦盘的破坏性步骤之前停下来确认。到了需要输入管理员密码的地方,也停下来交还控制。
切换服务
这又是一个重复、耗时、但不能乱来的任务,所以继续沿用同一套流程:plan,refine,validate,finalize,然后 execute。
验证阶段最关心的是新的 Traefik gateway 和自动化流量切换。Agent 先用一次性资源证明新路径能工作:临时 tunnel 返回 HTTP 200,ACME 证书可以通过这个 tunnel 正常签发,IaC 也能创建并销毁测试 tunnel。高风险动作先在沙盒里验证,再动真实资源。
真正迁移时,每个服务都按同一个循环走:检查源配置,只停这一个 stack,做带 checksum 的 cold backup 到 NAS,在新主机上恢复,用 Ansible 部署,在 LAN 内验证,然后让旧 stack 保持停止但数据不删,作为回滚点。一次只迁一个服务,每个服务都能独立回滚。
当然不是所有事情都顺利,这也正是 Agent 有价值的地方。迁移 Pi-hole 这个私有 DNS 服务后,Docker 层看起来是健康的,但 DNS 会间歇性掉线,因为容器里的 FTL engine 会停。Agent 顺着日志挖下去,最后定位到 nebula-sync:在某些条件下,同步进程会覆盖正在运行的 Pi-hole,把它带下线。理解根因之后,Pi-hole 和 nebula-sync 都被放到 Ansible 管理下面,让配置和生命周期变成确定的,而不是两个进程互相 race。这种慢、证据驱动的 root-cause 分析,正是很适合交给 Agent 的繁琐工作。
公开流量切换是最谨慎的一步。新的 tunnel 用 OpenTofu 管理,但旧 tunnel 没有 IaC,不值得冒险把一个可用配置 import 或改坏。所以最终还是在浏览器里手动编辑旧 tunnel,一条 route 一条 route 切过去。这个过程比预期顺利。
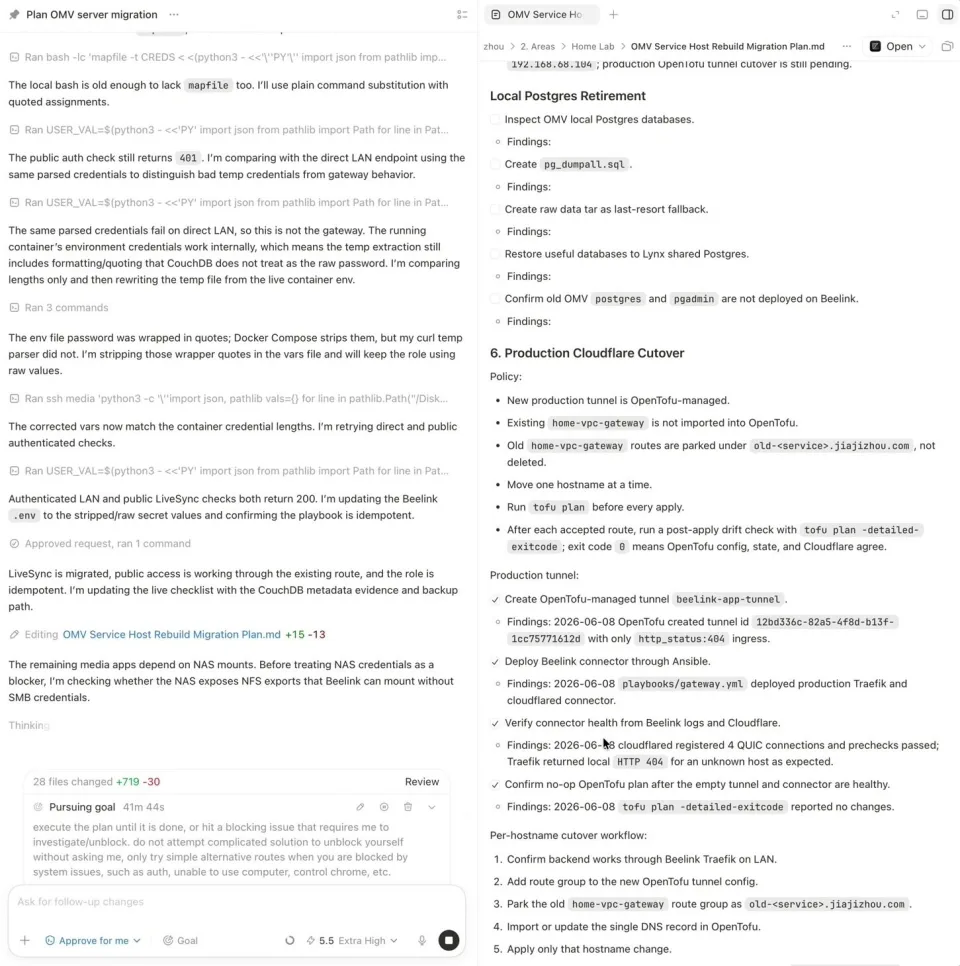
Agent 直接在计划文档里推进服务迁移 checklist,同时把它维护成执行日志。
最后 Codex 统计,这个 /goal 花了 两小时执行时间。真实耗时更长,因为中间有几个点需要人做判断,或者解锁 Agent 不能安全决定的事情。
最后的结果
整体看,这次重建很值。现在的 homelab 更省电、更可靠、更容易从源码重建,也比之前运行过的任何版本都更容易理解。
同时也验证了一套利用 Agent 处理复杂流程的方法。实现细节可以交给 Agent,但路线不能让它随意发挥:先一起把步骤推敲清楚,把含糊的地方补上,高风险步骤提前验证,再要求它在执行时记录每一步做了什么。对我有效的循环很简单:plan → refine → smoke-test → finalize → execute。再配合 /goal,一个原本很吓人的周末迁移,变成了可以监督、而不是亲手操作的过程。
信任边界也更清楚了。Agent 可以检查配置、写计划、执行迁移、重试安全步骤、维护操作日志。物理动作、秘密信息、破坏性批准,以及服务怎么拆、怎么暴露这类判断,仍然留给人。这个分工让整个过程是可控的,而不是靠感觉赌一把。
主要问题是成本,以及工具本身不够稳定。长 session 会烧 token,尤其是 Browser Use 或 Computer Use 卡住时,Agent 很容易开始自己找绕路方案。比较有效的做法是提前说清楚:如果认证坏了,或者 UI 工具不响应,就停下来问,不要自由发挥。
现在还不是完美状态,但它已经改变了我管理身边系统的方式。下一次硬盘坏掉,或者想加一个服务,不一定要先空出一个周末。先写清目标和计划,然后交给 /goal 往前推进。